Case Study - EU Parliament Text Sentiment Analysis
Sentiment analysis and classification on transcripts from European Union Parliament sessions.
- Client
- UC Berkeley Department of Political Science
- Year
- Service
- NLP Modeling & Research
Overview
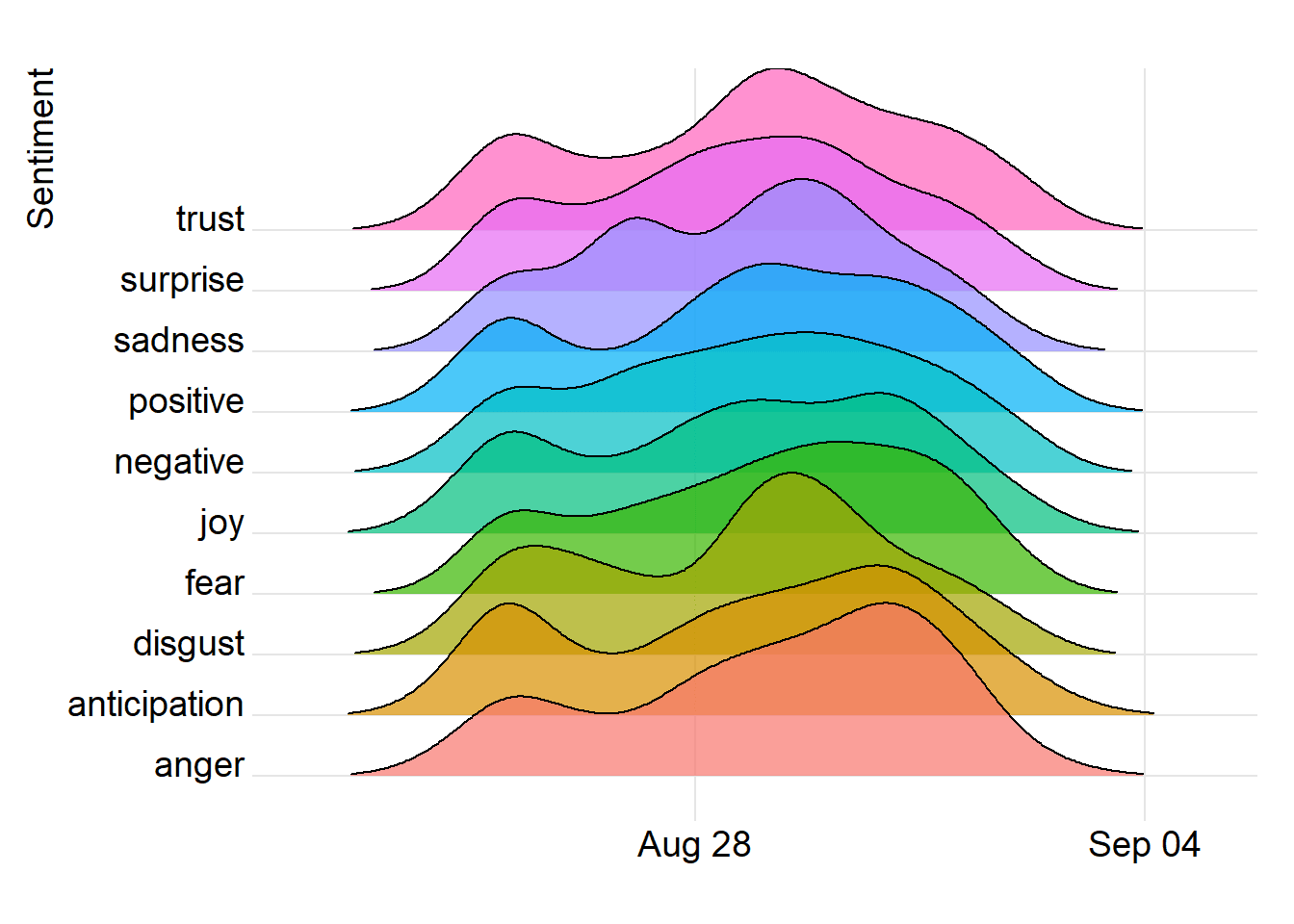
The UC Berkeley department of Political Science researches ways to use Machine Learning to detect trends in or make predictions about political events. One project we worked on involved training a sentiment analysis model on transcriptions from EU Parliament sessions in order to gague the emotions of members and measure "Euroskepticism"--how skeptical they are of the European Union.
Using a collection of over 3,000 EU parliamentary texts, we enhanced a text classification scheme to evaluate the Euroskepticism of each. This was achieved through the creation of a sentiment analysis ML model using Keras, Scikit-learn, which was supported by the Universal Sentence Encoder (USE).
In addition, through the implementation of imbalanced-learn oversampling techniques to compensate for the skewed training data set, the model's performance was significantly improved, leading to a 70% increase in accuracy for sentiment prediction.
What we did
- Machine Learning
- Text Classification
- Sentiment Analysis
- Sampling
Sentiment analysis is an extremely valuable application of natural language processing, especially when intersected with humanities research.

Software & Machine Learning Engineer